














Introduction on Data Engineering
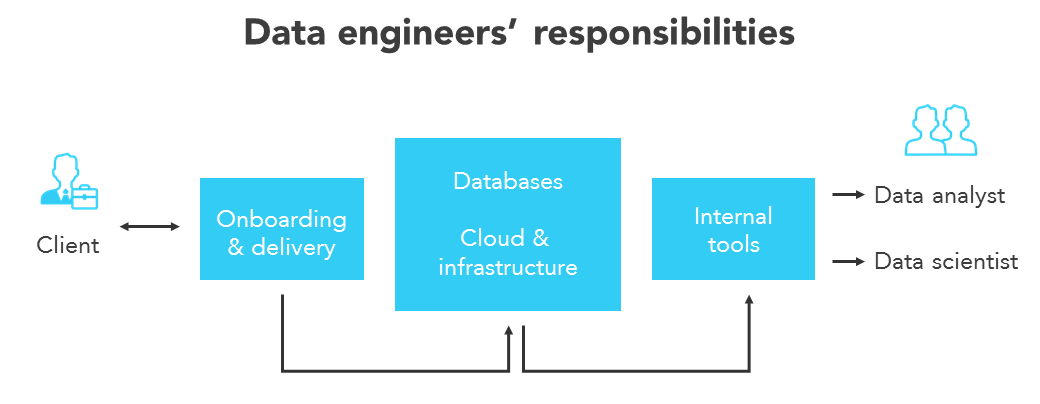
The process of designing and building large-scale data collection, storage, and analysis systems is known as data engineering. It’s a broad topic with applications in nearly every business. Large volumes of data can be collected, but the correct people and technology are required to ensure that the data is usable by the time it reaches data scientists and analysts.

If we look at the hierarchy of demands in data science implementations, we can see that data engineering is the next stage after acquiring data for analysis. This discipline should not be overlooked because it allows for efficient data storage and dependable data flow while also managing the infrastructure. Without data engineers to analyze and channel that data, fields like machine learning and deep learning won’t prosper.
What is Data Engineering?
Data engineering is a series of processes aimed at building information flow and access interfaces and procedures. Maintaining data such that it is available and usable by others necessitates the use of dedicated specialists – data engineers. In a nutshell, data engineers put up and maintain the organization’s data infrastructure, ready it for analysis by data analysts and scientists.
Let’s start with data sources to grasp data engineering in simple words. There are frequently several various types of operations management software (e.g., ERP, CRM, production systems, etc.) within a large firm, all of which contain different databases with different information.
Furthermore, data can be saved as distinct files or even fetched in real-time from external sources (such as various IoT devices). As the number of data sources grows, having data fragmented across multiple formats prohibits an organization from receiving a complete and accurate picture of its financial situation.
For example, sales data from a specialized database must be linked to inventory records in a SQL server. This operation entails pulling data from those systems and integrating it into a centralized storage system, where it is collected, reformatted and maintained ready to use. Data warehouses are storage facilities like this. Data engineers manage the process of migrating data from one system to another, whether it’s a SaaS service, a Data Warehouse (DW), or just another database.
ETL Data Pipeline
A data pipeline is essentially a collection of tools and methods for transferring data from one system to another for storage and processing. It collects data from several sources and stores it in a database, another tool, or an app, giving data scientists, BI engineers, data analysts, and other teams quick and dependable access to this combined data.

Data engineering is primarily responsible for constructing data pipelines. Designing a program for continuous and automated data interchange necessitates considerable programming skills. A data pipeline is a tool that can be used for a variety of tasks:
- Transferring data to a data warehouse or the cloud.
- Gathering data into a single spot for machine learning projects’ convenience.
- In the Internet of Things (IoT), data from numerous linked devices and systems are combined.
- Transferring databases to a cloud-based data warehouse and,
- BI brings data together in one location for better business choices.
Data pipeline challenges
It’s difficult to set up a secure and dependable data flow. Many things can go wrong during data transport: data can be damaged, bottlenecks can cause slowness, and data sources can conflict, resulting in duplicate or inaccurate data. To obscure sensitive information while not missing vital data, rigorous planning and testing are required to filter out trash data, eliminate duplicates, and incompatible data types.
Building data pipelines has two key pitfalls:
- Lack of meaningful metrics and
- Underestimation of data load.
ETL & ELT
ETL refers to extracting, transforming and loading. Pipeline infrastructure varies in size and scope based on the use case. Data engineering, on the other hand, frequently begins with ETL operations.
- Extract: The process of obtaining data from a source system is known as extraction. For instance, a python process to retrieve data from an API, access data from an OLTP database, and so on.
- Transform: The process of transforming the data that has been extracted. Changing field types and names, implementing business logic on the data set, enhancing data, and so on.
- Load: The process of loading transformed data into the data asset used by the end-user is referred to as loading.
After the data has been translated and imported into a single storage location, it may be used for further analysis and business intelligence tasks, such as reporting and visualization.
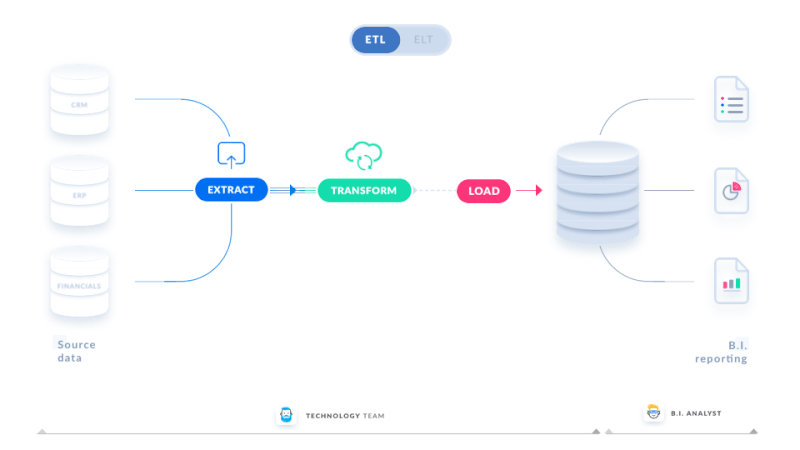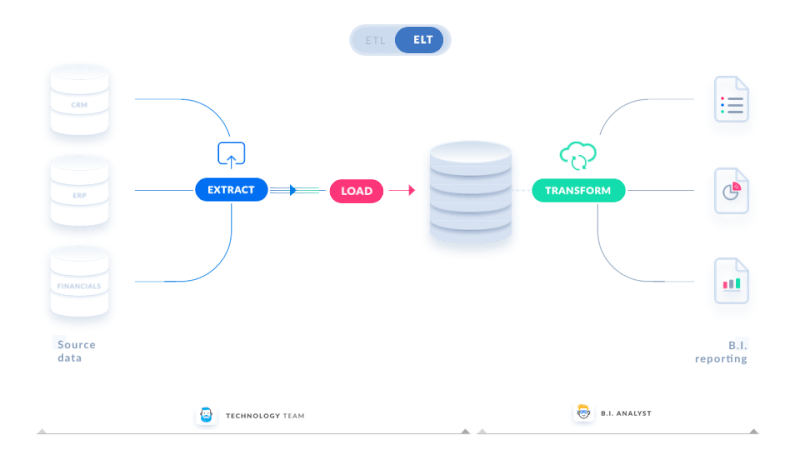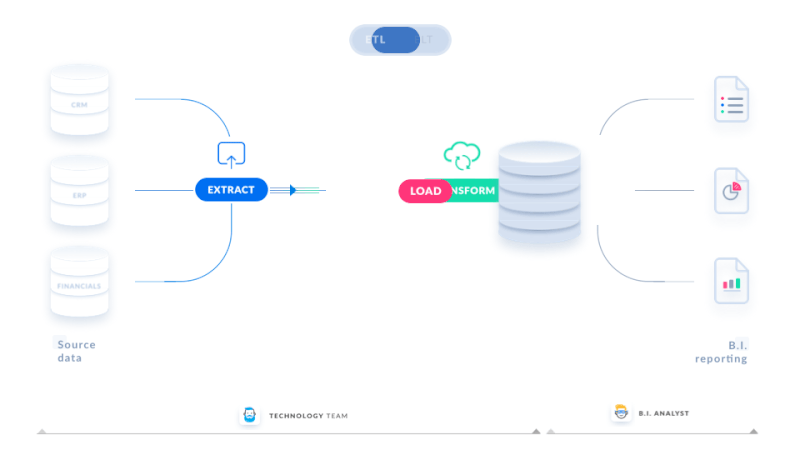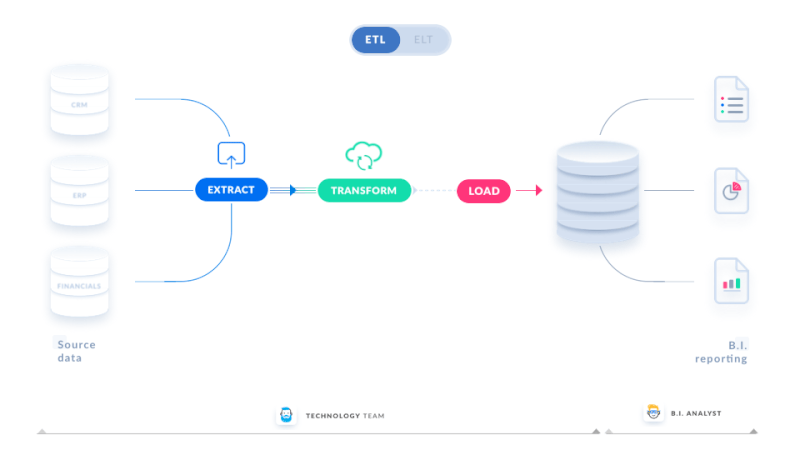
Source: Linkedin.com
ETL has traditionally been used to refer to any data pipeline in which data is extracted from a source, transformed, and loaded into a final table for end-user usage. The transformation could be done in Python, Spark, Scala, or SQL in the data warehouse, among other languages. ELT is a term that has been used to describe data pipelines that convert data in a data warehouse.
When individuals mention ETL and ELT, they’re referring to
- ETL: The raw data is saved in a file system, then converted using python/spark/scala or other non-SQL languages before being imported into tables for end-user use.
- ELT: The raw data is entered into the data warehouse and SQL is used to transform it into the final table that the end-user may use.
Data Warehouse
A data warehouse is a database that stores all of your company’s historical data and allows you to conduct analytical queries against it. A data warehouse is a relational database that is optimized for reading, aggregating and querying massive amounts of data from a technical point of view. Traditionally, data warehouses (DWs) exclusively held structured data or data that could be organized into tables. Modern DWs, on the other hand, can integrate structured and unstructured data.
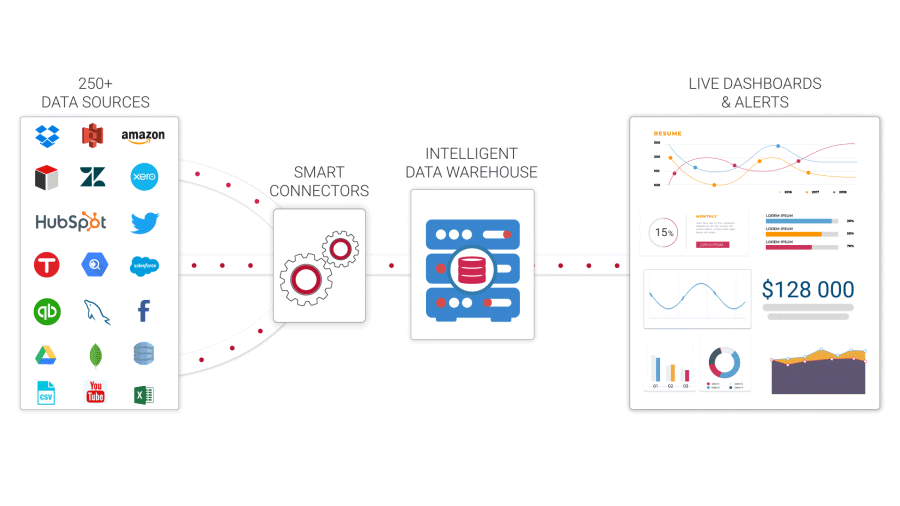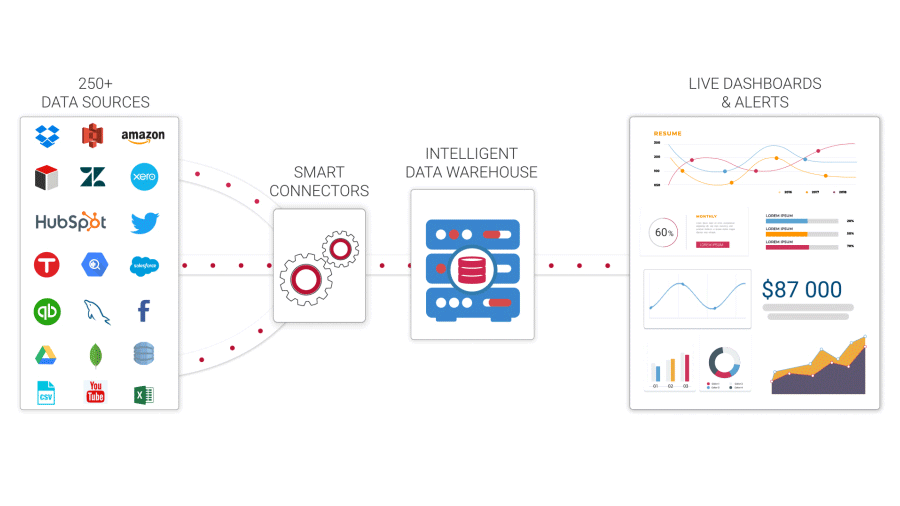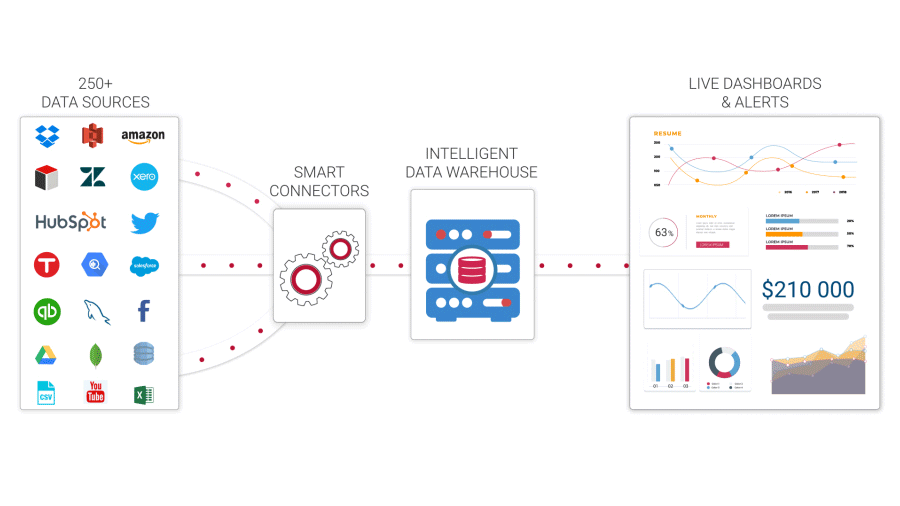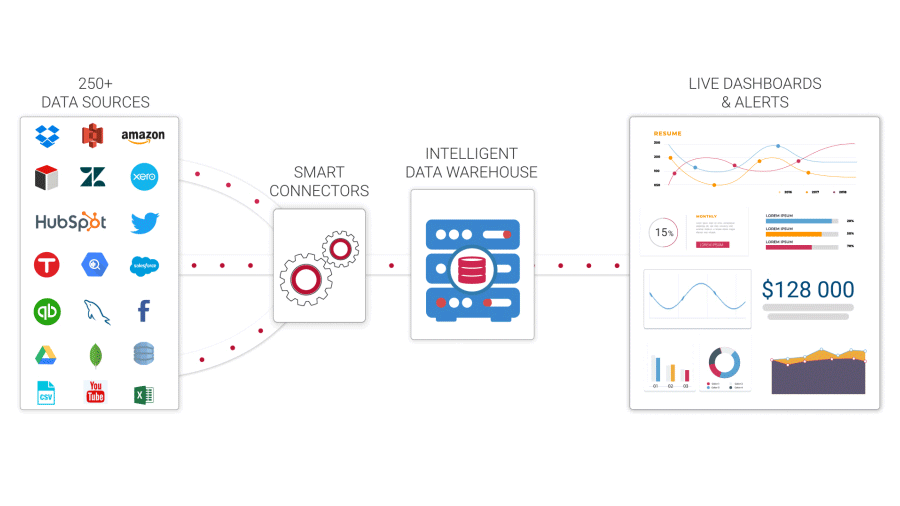
Without data warehouses, data scientists would have to take data directly from the production database, which could result in different answers to the same inquiry, as well as delays and interruptions. The data warehouse, which serves as an organization’s single source of truth, streamlines reporting and analysis, decision-making, and metrics forecasting.
Four essential components are combined to create a data warehouse:
- Data warehouse storage.
- Metadata.
- Data warehouse access tools.
- Data warehouse management tools.
Data Engineering: Moving Beyond Just Software Engineering
Software engineering is well-known for its programming languages, object-oriented programming, and operating system development. However, as businesses experience a data explosion, traditional software engineering thinking fails to process big data. Data engineering helps firms to collect, generate, store, analyze, and manage data in real-time or in batches while constructing data infrastructure, thanks to a new set of tools and technologies.
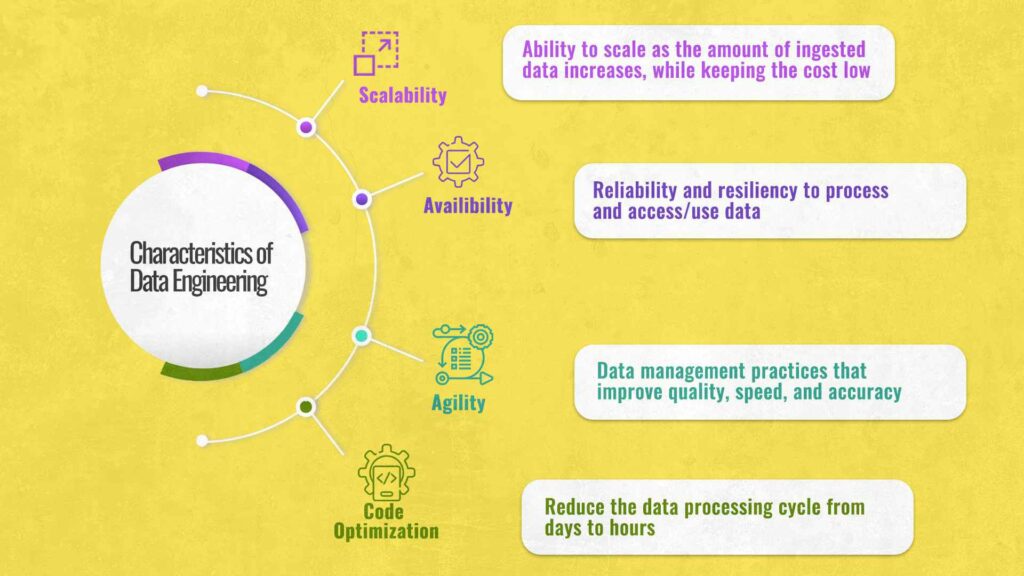
Traditional software engineering approaches entail mostly stateless software design, programming, and development. Data engineering, on the other hand, focuses on scaling stateful data systems and dealing with various levels of complexity. In terms of scalability, optimization, availability, and agility, there are also disparities in the complexity of the two fields.
Sample Python Code
MongoDB is a document-based NoSQL database that scales effectively. We’ll begin by importing relevant Python libraries.
Here’s how to make a database and populate it with data:
import pymongo client = pymongo.MongoClient("mongodb://localhost:27017/")# Note: This database is not created until it is populated by some data db = client["example_database"] customers = db["customers"] items = db["items"] customers_data = [{ "firstname": "Bob", "lastname": "Adams" },
{ "firstname": "Amy", "lastname": "Smith" },
{ "firstname": "Rob", "lastname": "Bennet" },]
items_data = [{ "title": "USB", "price": 10.2 },
{ "title": "Mouse", "price": 12.23 },
{ "title": "Monitor", "price": 199.99 },]customers.insert_many(customers_data) items.insert_many(items_data) |
Conclusion
There’s no denying that data engineering is a fast-growing field. It is, however, a new space. The entire landscape of business operations is being challenged by data engineering, and there has never been a better time for prospective individuals to dive into this ever-evolving subject.





{kind=link}