

Getting Started:
Machine learning tasks can be broadly classified into 3 broad categories: supervised, unsupervised, and reinforcement learning, depending on the presence of target class or business constraints.
Scikit-learn documentation offers an estimator selection flowchart-based cheat-sheet, that can help data scientists to understand and choose the right machine learning algorithm for their data.

(Source), Scikit-learn cheat-sheet to choose the right estimator
The above-mentioned flowchart image explains data scientists a rough idea to choose the right scikit-learn estimator. In this article, we will discuss in detail the above flowchart and understand the reason behind each decision.
In the above flowchart, the blue circles refer to the condition choice. For each condition are outcomes are depicted by red, green, or orange arrows describing yes, no, and not working respectively. The green rectangles are the individual machine learning algorithms.
1. Classification:
The training data should at least have a few hundred of instances to train a robust model. For the classification tasks, the target class should be discrete.
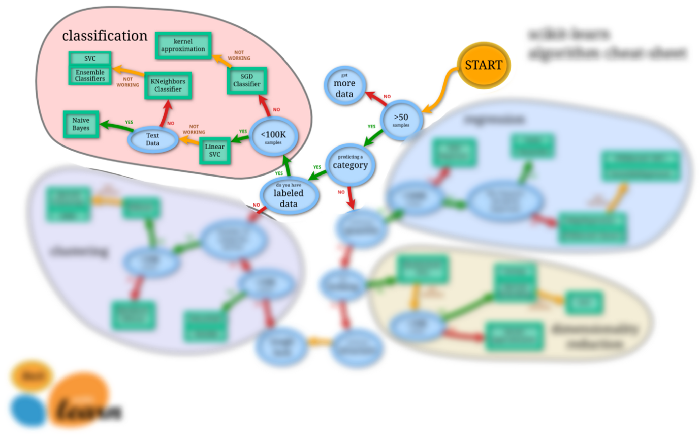
(Source), Scikit-learn cheat-sheet to choose the right estimator for classification tasks
SVC, Naive Bayes, k-NN are some of the popular classification estimators but have comparatively high time complexity. For data with <100k samples, one can try the Linear SVC model. For textual data Linear SVC model might not perform well, so one can try the Naive Bayes classifier, which works quite well with text features. For non-text features, the k-NN machine learning algorithm is a good choice.
For samples,>100k one can try an SGD classifier with kernel approximations, that has comparatively less time complexity. If these models show low performance, high bias, or high variance problems, then one can even try some ensembles techniques.
2. Regression:
Scikit-learn package offers the implementation of various regression estimators for a dataset with continuous target class labels.
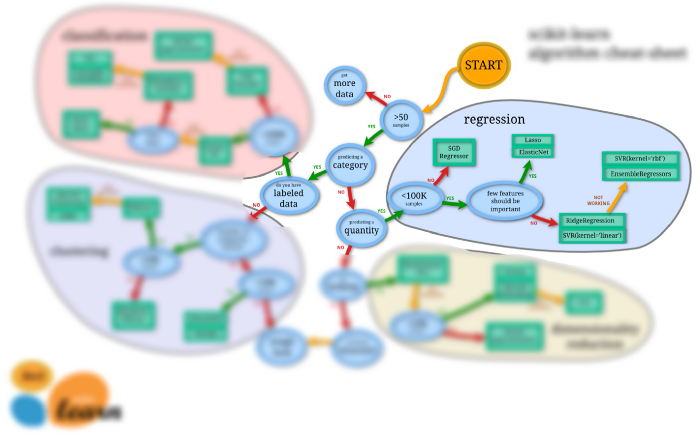
(Source), Scikit-learn cheat-sheet to choose the right estimator for regression tasks
Same as classification tasks, for data with >100k samples SGD regressor with kernel approximation can be preferred as it has competitively less time complexity.
For data with <100k samples, Lasso regression or elastic net regression can be used for data with large dimensionality, else Ridge regression can be chosen.
If these models show low performance, high bias, or high variance problems, then one can even try some ensembles techniques.
3. Clustering:
For unsupervised tasks, the scikit-learn package offers various clustering packages.
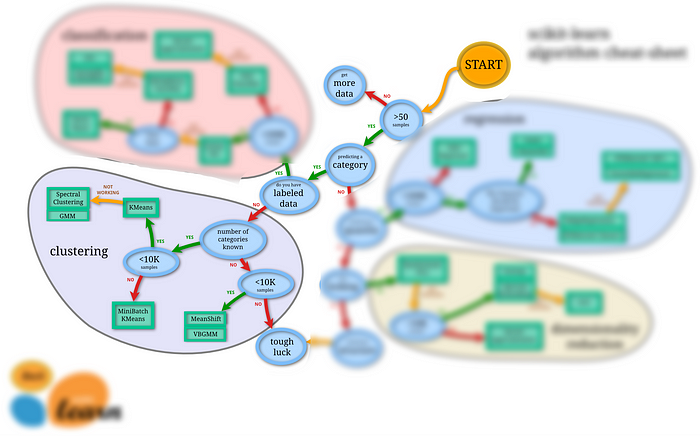
(Source), Scikit-learn cheat-sheet to choose the right estimator for clustering tasks
k-Means is a popular clustering technique but has high time complexity. For a large sample of data, one can try a variation of k-Means clustering called mini-batch k-means. Spectral Clustering algorithms like Gaussian mixture clustering can be trained if k-Means does not perform well.
If the number of clusters is predefined by business folks, then one can try VBGMM (Variational Inference for the Gaussian Mixture Model).
4. Dimension Reduction:
Dimension reduction techniques are used to reduce the dimensionality of the data, by projecting the existing data into a new space or dimension. Scikit-learn package offers various dimension reduction techniques discussed below.

(Source), Scikit-learn cheat-sheet to choose the right estimator for dimension reduction tasks
PCA is a popular dimension reduction technique that uses eighen vector or eighen values to reduce the dimensionality of the data. For small samples of data, one can try spectral embedding techniques such as Isomap or t-SNE.
Conclusion:
In this article, we have discussed a cheat sheet or set of rules that can be followed to choose the right estimator for your dataset. The above-discussed rules or machine learning algorithms are restricted to scikit-learn packages.