














Machine learning algorithms can cause the “black box” problem, which means we don’t always know exactly what they are predicting. This may lead to unwanted consequences. In the following tutorial, Natalie Beyer will show you how to use the SHAP (SHapley Additive exPlanations) package in Python to get closer to explainable machine learning results.
In this tutorial, you will learn how to use the SHAP package in Python applied to a practical example step by step.
Motivation
Machine Learning is used in a lot of contexts nowadays. We get offers for different products, recommendations on what to watch tonight and many more. Sometimes the predictions fit our needs and we buy or watch what was offered. Sometimes we get the wrong predictions. Sometimes those predictions are in more sensitive contexts than watching a show or buying a certain product. For example, when an algorithm that is supposed to automate hiring decisions discriminates against a group. Amazons recruiters used an algorithm that was systematically rejecting women before inviting them to job interviews.
To make sure that we know what the algorithms we use actually do, we have to take a closer look at what we are actually predicting. New methods of explainable machine learning open up the possibility to explore which factors were used exhaustively by the algorithm to come to the predictions. Those methods can lead to a better understanding of what the algorithm is actually doing and whether it emphasizes columns that should not contain much information.
Example
To have a clearer picture of explainable AI, we will go through an example. The used dataset consists out of Kickstarter projects and can be downloaded here. Kickstarter is a crowdfunding platform where people can upload a video or description about their planned projects. If one would like to support a project, he or she can donate money to that project. In this example, I would like to guide you through a machine learning algorithm that is going to predict whether a given project is going to be successful or not. The interesting part is that we are going to take a look at why the algorithm came to a certain decision.
This explainable machine learning example will be in Python. So, at first we need to import a few packages (Listing 1). pandas, NumPy, skikit-learn and Matplotlib are frequently used in data science projects. CatBoost is a great tree based algorithm that can deal excellently with categorical data and has a good performance also in the default settings. SHAP is the package by Scott M. Lundberg that is the approach to interpret machine learning outcomes.
1 2 3 4 5 6 7 | import pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_splitimport matplotlib.pyplot as pltimport catboost as catboostfrom catboost import CatBoostClassifier, Pool, cvimport shap |
Used versions of the packages:
- pandas 0.25.0
- NumPy 1.16.4
- Matplotlib 3.0.3
- skikit-learn 0.19.1
- CatBoost 0.18.1
- SHAP 0.28.3
Let’s take a look at the downloaded dataset (Figure 1) with kickstarter.head():
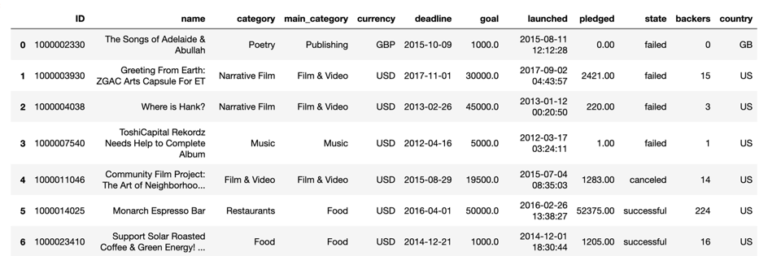
Figure 1
The first column is the identification number of each project. The name column is the name of the Kickstarter project. category classifies each project in one of 159 different categories. Those categories can be summed up into 15 main categories. Next is the currency of the project. The column deadlinerepresents the last possible date to support the project. pledged describes the amount of money that was given in order to support the project. state is the state of the project after the deadline date. backers is defined as the number of supporters for the given project. The last column consists out of the country in which the project was launched.
We are just going to use the states failed and successful, as the other states like canceled do not seem to be very interesting (Listing 2).
1 | kickstarter["state"] = kickstarter["state"].replace({"failed": 0, "successful": 1}) |
First machine learning model
We are going to start with a machine learning model that takes the following columns as the feature vector (Listing 3):
1 2 3 4 5 6 7 8 9 10 11 12 13 | kickstarter_first = kickstarter[ [ "category", "main_category", "currency", "deadline", "goal", "launched", "backers", "country", "state", ]] |
The last column is going to be our target column, therefore y. All the other columns are the feature vector, therefore X (Listing 4).
1 2 | X = kickstarter_first[kickstarter_first.columns[:-1]]y = kickstarter_first[kickstarter_first.columns[-1:]] |
We are going to split the dataset with the result of having 10% of the dataset as the test dataset, and 90% as the training dataset (Listing 5).
1 2 3 | X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.1, random_state=42) |
As our classifier, I chose CatBoost, as it can deal very well with categorical data (Listing 6). We are going to take the preinstalled settings of the algorithm. Also, 150 iterations are enough for our purposes.
1 2 3 | model = CatBoostClassifier( random_seed=42, logging_level="Silent", iterations=150) |
In order to use CatBoost properly, we need to define which columns are categorical (Listing 7). In our case, those are all columns that have the type object.
1 2 | categorical_features_indices = np.where(X.dtypes == np.object)[0]X.dtypes |

Figure 2
We can see in Figure 2 that all columns but goal and backers are object columns and should be treated as categorical.
After fitting the model, we see a pretty good result (Listing 8):
1 2 3 4 5 6 | model.fit( X_train, y_train, cat_features=categorical_features_indices, eval_set=(X_test, y_test),) |
Figure 3
With this first model, we are able to classify 93% of our test dataset correctly (Figure 3).
Let’s not get too excited and check out what we are actually predicting.
With the package SHAP, we are able to see which factors were mostly responsible for the predictions (Listing 9).
1 2 3 4 5 6 7 8 | shap_values = model.get_feature_importance( Pool(X_test, label=y_test, cat_features=categorical_features_indices), type="ShapValues",)shap_values = shap_values[:, :-1]shap.summary_plot(shap_values, X_test, plot_type="bar") |
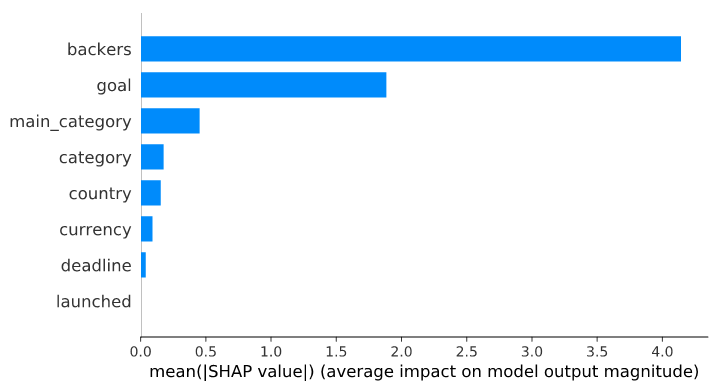
Figure 4
With this bar plot (Figure 4), we can see that the column backers is contributing the most to the prediction!
Oh no! We have put an approximation of the target column (status failed or successful) into our model. If your Kickstarter project has a lot of backers, then it is most likely going to be successful.
Let’s give it another go. This time we are just going to use the columns that are not going to reveal too much information.
Second machine learning model
In the extended dataset kickstarter_extended = kickstarter.copy(), we are going to implement some feature engineering. Looking through the data, one can see that some projects are using special characters in their name. We are going to implement a new column number_special_character_name that is going to count the number of special characters per name (Listing 10).
1 2 3 4 | kickstarter_extended[ "number_special_character_name"] = kickstarter_extended.name.str.count('[-()"#/@;:<>{}`+=~|.!?,]')kickstarter_extended["word_count"] = kickstarter_extended["name"].str.split().map(len) |
Also, we are going to change the deadline and launched column from the type object to datetimeand thereby replace the columns. This is happening in order to get the new column delta_days, which consists out of the days between the “launched” date and the “deadline” date (Listing 11).
1 2 3 4 5 6 | kickstarter_extended["deadline"] = pd.to_datetime(kickstarter_extended["deadline"])kickstarter_extended["launched"] = pd.to_datetime(kickstarter_extended["launched"])kickstarter_extended["delta_days"] = ( kickstarter_extended["deadline"] - kickstarter_extended["launched"]).dt.days |
It is also interesting to see whether projects are more successful in certain months. Therefore, we are building the new column launched_month. The same for day of week and year (Listing 12).
1 2 3 4 5 6 | kickstarter_extended["launched_month"] = kickstarter_extended["launched"].dt.monthkickstarter_extended[ "day_of_week_launched"] = kickstarter_extended.launched.dt.dayofweekkickstarter_extended["year_launched"] = kickstarter_extended.launched.dt.yearkickstarter_extended.drop(["deadline", "launched"], inplace=True, axis=1) |
The new dataset kickstarter_extended now consists of the following columns (Listing 13):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | kickstarter_extended = kickstarter_extended[ [ "ID", "category", "main_category", "currency", "goal", "country", "number_special_character_name", "word_count", "delta_days", "launched_month", "day_of_week_launched", "year_launched", "state", ]] |
Again, building the test and training dataset (Listing 14).
1 2 3 4 5 6 | X = kickstarter_extended[kickstarter_extended.columns[:-1]]y = kickstarter_extended[kickstarter_extended.columns[-1:]]X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.1, random_state=42) |
Initializing the new model and setting the categorical columns. Afterwards, fitting the model (Listing 15).
1 2 3 4 5 6 7 8 9 10 11 12 13 | model = CatBoostClassifier( random_seed=42, logging_level="Silent", iterations=150)categorical_features_indices = np.where(X_train.dtypes == np.object)[0]model.fit( X_train, y_train, cat_features=categorical_features_indices, eval_set=(X_test, y_test),)model.score(X_test, y_test) |
Figure 5
The current model is a little bit worse than the first try (Figure 5), but the assumption is that we are now actually predicting on a more accurate database. A quick look at the bar plot, generated by Listing 16 and containing the current feature importances, tells us that in fact goal is the most informative column now (Figure 6).
1 2 3 4 5 6 7 | shap_values_ks = model.get_feature_importance( Pool(X_test, label=y_test, cat_features=categorical_features_indices), type="ShapValues",)shap_values_ks = shap_values_ks[:, :-1]shap.summary_plot(shap_values_ks, X_test, plot_type="bar") |
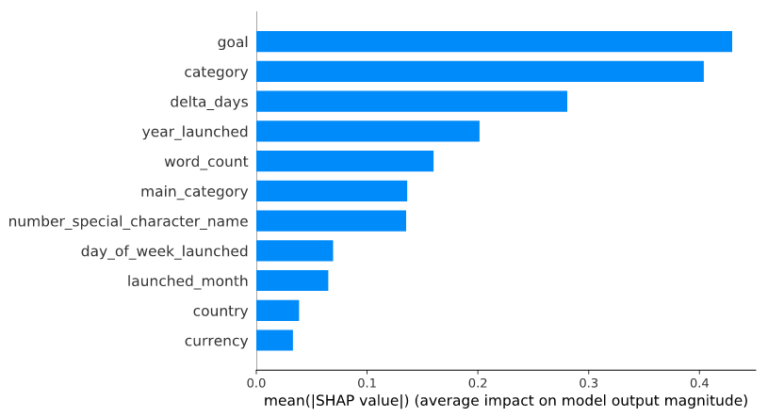
Figure 6
Until now, the SHAP package did not show anything other algorithm libraries cannot do. Showing feature importances has already been implemented in XGBoost and CatBoost some versions ago.
But now let’s get SHAP to shine. We enter shap.summary_plot(shap_values_ks, X_test) and receive the following summary plot (Figure 7):
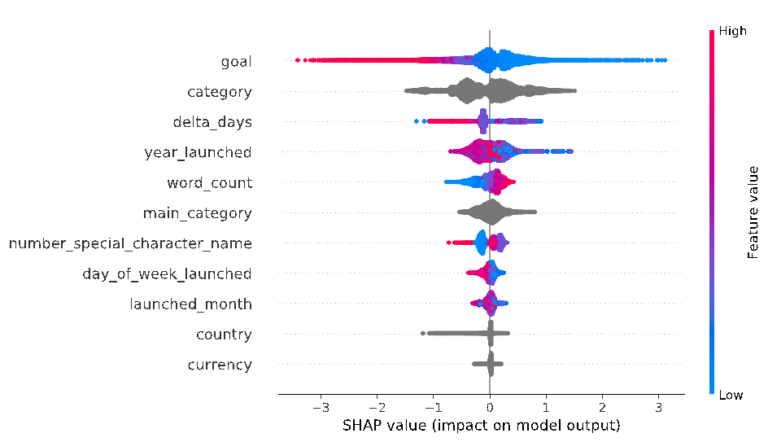
Figure 7
In this summary plot, the order of the columns still represents the amount of information the column is accountable for in the prediction. Each dot in the visualization represents one prediction. The color is related to the real data point. If the actual value in the dataset was high, the color is pink; blue indicates the actual value being low. Grey represents the categorical values which cannot be scaled in high or low. But the package maintainers are working on it. The x-axis represents the SHAP value, which is the impact on the model output. The model output 1 equates to the prediction of successful; 0 the prediction that the project is going to fail.
Let’s take a look at the first row of the summary_plot. If a Kickstarter project owner set the goal high (pink dots) the model output was likely 0 (negative SHAP value, not successful). It totally makes sense: if you set the bar for the money goal too high, you cannot reach it. On the other hand, if you set it very low, you are likely to achieve it by asking just a few of your friends. The column word_countalso shows a clear relationship: few words in the name description indicate a negative impact on the model output, in the sense that it is likely a failed project. Maybe more words in the name deliver more information, so that potential supporters already get interested after reading just the title. You can see that the other columns are showing a more complex picture as there are pink dots in a mainly blue area and the other way around.
The great thing about the SHAP package is that it gives the opportunity to dive even deeper into the exploration of our model. Namely, it will give us the feature contributions for every single prediction (Listing 17).
1 2 3 4 5 6 7 8 9 | shap_values = model.get_feature_importance( Pool(X_test, label=y_test, cat_features=categorical_features_indices), type="ShapValues",)expected_value = shap_values[0, -1]shap_values = shap_values[:, :-1]shap.initjs() shap.force_plot(expected_value, shap_values[10, :], X_test.iloc[10, :]) |

Figure 8
In the force plot (Figure 8), we can see the row at position 10 of our test dataset. This was a correct prediction of a successful project. Features that are pink contribute to the model output being higher, that means predicting a success of the Kickstarter project. Blue parts of the visualization indicate a lower model output, predicting a failed project. So the biggest block here is the feature ‘category’, which in this case is Tabletop Games. Therefore, with this particular set of information, the project being a Tabletop Game is the most informative feature for the model. Also, the short period of 28 days of the project being online contributes towards the prediction of success.
Another example is row 33161 of the test dataset, which was a correct prediction of a failed project. As we can see in the force plot (Figure 9), generated by Listing 18, the biggest block is the feature goal. Apparently, the set goal of $25,000 was too high.
1 | shap.force_plot(expected_value, shap_values[33161, :], X_test.iloc[33161, :]) |

Figure 9
So, now we got a better look at our model with this Kickstarter dataset. One could also explore the false predictions and get an even deeper understanding of the model. One can also take a look at the false positives and false negatives. There, you could see on which features the model concentrated that lead to an incorrect model output. There are also many other visualizations like interaction values. Check out the documentation if you are interested.
Outlook
The SHAP package is also useful in other machine learning tasks. For example, image recognition tasks. In Figure 10, you can see which pixels contributed to which model output.

Figure 10. Source: SHAP
SHAP is giving us the opportunity to better understand the model and which features contributed to which prediction. The package allows us to check whether we are taking just features into account which make sense. It is the first step towards preventing models from predicting things based on wrong input features. Thus, machine learning becomes less of a “black box”. This way, we are getting closer to explainable machine learning.





{kind=link}