













Introduction
Predicting and understanding weather has become crucial in a number of industries, including agriculture, autonomous driving, aviation, or the energy sector. For example, weather conditions play a significant role for aviation and logistics companies in planning the fastest and safest route. Similarly, renewable energy companies need to be able to predict the amount of energy they will produce at a given day. As a consequence various weather models have been developed and are being applied all over the world. Unfortunately, these models often require highly specific information about the atmosphere and exact conditions.
For this reason, Meteomatics, a weather API that delivers fast, direct and simple access to an extensive range of global weather, climate projections and environmental data, has reached out to us for help. Their goal: To predict precipitation accurately in regions where data is sparse and they have to rely on satellite imagery. In this blog post, we show how we developed a neural network to predict the amount of rainfall in a given region based on infrared satellite data.
Data collection and analysis
If you have ever worked with neural networks you know that they can be data hungry. For this reason it’s crucial to set up a data pipeline that allows you to collect, manage, and understand the assembled data. Our collaboration partner, Meteomatics, offers an easy-to-use API which enables us to quickly gather training and ground-truth data. For example, to get an infra-red picture of Europe (coordinates from 65, -15 to 35, 20) on the seventh of July 2021 and at a resolution of 800×600 pixels we can simply make the following query: https://towardsdatascience.com/media/53175d11672088cfbe121a48d17e391e Example query to get an infrared satellite image from meteomatics.com. The downloaded image can be seen in the example plot below on the left.
We ran a Python script every quarter hour for a few days collecting infra-red images over Europe, North America, and Mexico at different wavelengths. We then locally combined the different images for each timestamp into an RGB image. To make the task easier we masked out stratiform precipitationin a first step. However, as we will see later on, this only has a small effect on the accuracy of the model. We also collected ground-truth data for training and evaluating the accuracy of our model. Note that ground-truth data was only available for Europe and North America. Below you can see a pair of input and ground-truth data over Europe:

Following the notorious “garbage in garbage out” mantra, we wanted to understand and curate the collected data before we trained a machine learning algorithm on it. For this, we used our free-to-use exploration tool Lightly.ai. Lightly enables quick and easy ways to analyze a dataset as well as more in-depth algorithms to pick the most relevant training points. After uploading our dataset to Lightly we immediately noticed a crucial property of the collected data: The images over Europe, North America, and Mexico were visually and semantically separated. This resulted in a simple strategy to test the generalization capacity of the algorithm: If we trained it on the data from Europe and it performed well on unseen data from North America and Mexico, the algorithm would generalize well. Note that if we had picked the training dataset and the test dataset to be very similar, then all we would test is the memory of the neural network.
Another key insight we gained was that there were many small clusters of extremely similar images. This is due to the fact that we collected data over a relatively short period of time. Because of this, there were a lot of similar images in the dataset which made it harder for the model to generalize well. Lightly helped us with removing these redundancies with a method called “coreset sampling” which aims to maximize the diversity of the dataset.
Before curating the dataset with Lightly, we had 1158 images in our training dataset (Europe). After data curation, we are left with 578 images. The validation dataset (North America) consists of 1107 images and the test dataset (Mexico) consists of only 43 images as we began data collection later.
We download the images from Lightly and and now we are ready to do some machine learning.
Neural networks and semantic segmentation
Convolutional neural networks are a class of artificial neural networks applied in computer vision. Their shared-weight architecture allows them to efficiently process image data and to detect relevant features easily. Satellite images are perfectly suited for machine learning. The domain of possible input images is fairly limited as the satellite is always at the approximately same height and objects will therefore always appear at a similar scale.
Semantic segmentation is the task of assigning a label to each pixel of an image. For example, in autonomous driving an algorithm will often have to learn which pixels of an image represent a car, a pedestrian, a cyclist, a stop sign, and so on. You can read more about this here. A typical architecture of a neural network designed for semantic segmentation is the UNet (see image below). Here, the input image is converted into a dense vector by a pyramid of convolutional layers and then expanded again to the original shape of the image through a series of deconvolutional layers. Additionally, features from the convolutional and deconvolutional layers are shared in order to gain a global view of the input image.
For this task, we used a neural net called Efficient Neural Network (or ENet). Specifically, we used this PyTorch implementation. It’s a variant of UNet which is specialized for mobile applications and therefore requires fewer floating point operations and parameters. This results in shorter training and inference times.
In order to frame the task of predicting the amount of precipitation as a semantic segmentation problem, we split the output space into the following categories based on the amount of precipitation in millimeters over a timespan of five minutes:
- unlabeled (masked out part of the image if present)
- 0.00mm (no rain)
- 0.04mm — 0.07mm
- 0.07mm — 0.15mm
- 0.15mm — 0.30mm
- 0.30mm — 0.60mm
- 0.60mm — 1.20mm
- 1.20mm — 2.40mm
- 2.40mm — 4.80mm
- > 4.80mm
Results
We trained the neural network with the default settings from the cited repository except for changing the height and the width of the input to match the resolution of the images (600×800). Training 100 epochs on the complete dataset on a NVIDIA Tesla P100 took approximately 1.6 hours. When training on the curated dataset from above, we were able to cut down the training time by over 50%.
We will first report the results for the simpler case of predicting convective precipitation and later comment on the more general case. Table 1 below shows the IoU (intersection over union) of the predictions with the ground-truth annotations for the different classes on the training dataset (Europe) and the test dataset (North America).

As the numbers show, the model learned to differentiate between “rain” and “no-rain” with a very high accuracy. Unfortunately, the accuracy drops quickly with increasing precipitation. This can be explained by the sparsity of available data for areas experiencing large amounts of rain. The numbers in the table might suggest that the model performs rather poorly. However, this is not the case. We have asked an expert from Meteomatics to visually inspect the predictions made by our model and their conclusion was that the model is very accurate — especially considering the little amount of data it required. To give you a better understanding of the predictions made by the algorithm, we will walk you through some examples which Meteomatics used to do the visual inspection.
Figure 1 shows the infrared images, the ground-truth, and the predictions made by our algorithm for a weather situation over Europe (training set). We can see immediately that the shape of the prediction is very accurate. However, we also observe that the number of pixels where the model predicts high precipitation (shown in red) is rather low. This is a typical example of an imbalanced dataset and collecting more data of high precipitation would likely resolve the problem. It’s also noticeable that the model fails to predict the fine grained details of the ground-truth data accurately. This could be dealt with by increasing the resolution.
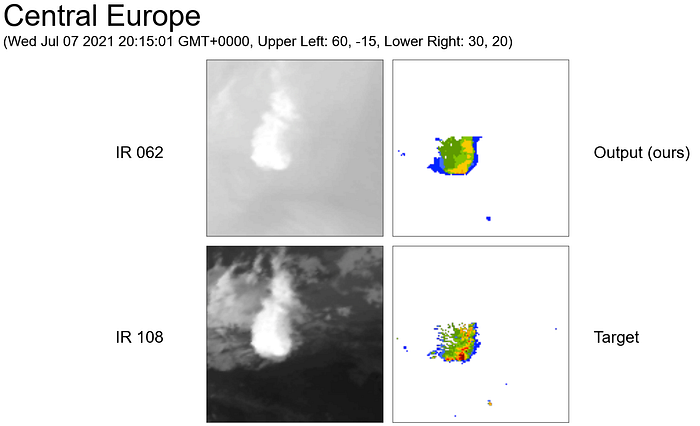
Figure 2 shows the infrared images, the ground-truth, and the predictions made by our algorithm for a weather situation over North America (test set). Similar to the situation in the training set, we can see that the predictions made for areas of high precipitation are less accurate. However, the model correctly predicts the shape of the ground-truth and has a tendency to accurately predict the areas where there is more precipitation.

Lastly, we want to compare our algorithm to one which is already in production. Figure 3 shows again the infrared images and the predictions made by our algorithm, this time over Mexico. However, instead of the ground-truth, it shows the predictions made by a physical model of the clouds and atmosphere. It’s evident that the outputs differ strongly and that, based on the input images, our algorithm seems to outperform the physical model at least in terms of precision. Indeed, fewer false positives are observed with our (the Lightly) algorithm, as precipitation is not predicted where there are no clouds.

Conclusion
In this series we developed a semantic segmentation model which predicts the amount of precipitation at a given location based on satellite images with good accuracy. Real-life applications of our convolutional neural network could play a crucial role in improving or complementing existing weather models and thus will help our collaboration partner, Meteomatics, to predict precipitation accurately in regions where data is difficult to acquire.
We can conclude that it is possible to achieve reasonable results when trying to predict precipitation from infrared satellite images with as little as 500 images. Even for the harder case where the stratiform precipitation is considered, the performance only drops slightly (by an IoU of approximately 0.04 on average). A key problem of the setting is the fact that the dataset is heavily imbalanced. To alleviate this, more training samples could be collected over a longer period of time to ensure a diverse dataset. For more fine grained results, it would be a good idea to collect images at a higher resolution and cut them into smaller chunks to keep the memory footprint low.
Finally, we note that diversifying the dataset with Lightly’s coreset algorithm improved the validation accuracy slightly while reducing training time by approximately 50%. This further validates the point that the imbalances and redundancies in this dataset can cause problems for model training.
Hopefully, this blog post has provided an example of the importance of data curation and the power of neural networks in weather models and will inspire the reader to try to build their own models with the help of Lightly and Meteomatics.
Philipp Wirth
Machine Learning Engineer
lightly.ai





{kind=link}