













In recent years, within the world of Artificial Intelligence, one of the most popular applications is Speech recognition. This popularity is due to the huge diversity of applications and needs : call center, broadcasting, traduction, health care, banking, voice assistant, etc.
Speech recognition includes various functionalities :
- Speech-to-Text: allows you to transcribe audio into text
- Text-to-Speech: allows you to transcribe a text into audio
- Speech Analysis: allows to analyze an audio speech in order to extract information such as: gender, age, emotions of the speaker
- Speech Diarization: Allows you to identify and differentiate the different speakers speaking in the same audio (by accents, specificities, etc.)
- Speech Translation: allows to translate an audio speech from a specific language into an audio speech from another language
This list does not represent an exhaustive list of all speech recognition functionalities. Many solutions are based on several functionalities combined.
This article briefly treats how to use Speech-to-Text with Python. We will see on this article that there are many ways to do it, including open source and cloud APIs engines.
Open source engines are available for free, you can often find those solutions on github. You just need to download the library and use these engines directly from your machine. On the contrary, speech-to-text cloud engines are provided by AI providers, they are selling you requests that you can process via their APIs. They can sell requests with a license model (you pay a monthly subscription corresponding to a certain amount of requests) or a pay-per-use model (you pay only for requests you send).
How to choose between open source and cloud engines ?
When you are looking for a speech-to-text engine, the first question you need to ask you is: which kind of engine am I going to choose?
Of course, the main advantage of open source speech-to-text engines is that they are open source. It means that this is free to use and you can use the code in the way you want. It allows you to potentially modify the source code, hyperparameterize the model. Moreover, you will have no trouble with data privacy because you will have to host the engine with your own server, which also means that you will need to set up this server, maintain it and insure you that you will have enough computing power to handle all the requests.
On the other hand, cloud speech-to-text engines are paying but the AI provider will handle the server for you, maintain and improve the model. In this case, you have to accept that your data will transit to the provider cloud. In exchange, the provider is processing millions of data to provide a very performant engine. The speech-to-text provider also has servers that can support millions of requests per second without losing performance or rapidity.
Now that you know the pros and cons of open source and cloud engines, please consider that there is a third option: build your own speech-to-text engine. With this option, you can build the engine based on your own data which guarantees you good performance. You will also be able to keep your data safe and private. However, you will have the same constraint of hosting your engine. Of course, this option can be considered only if you have data science abilities in your company. Here is a summary of when to choose between using existing engines (cloud or open source) and build your own one:

Ready-to-use VS Handmade AI engines
Open Source speech-to-text engines:
There are multiple open source speech-to-text engines available, you can find the majority on github. Here are the most famous ones:
DeepSpeech
DeepSpeech is an open-source Speech-To-Text engine, using a model trained by machine learning techniques based on Baidu’s Deep Speech research paper. Project DeepSpeech uses Google’s TensorFlow to make the implementation easier.
Here is how to install DeepSpeech package:

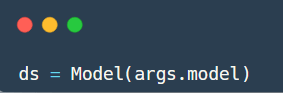
Then you can create a model instance and load model:
Finally, you can perform predictions:

Flashlight ASR
Flashlight is a fast, flexible machine learning library written entirely in C++ from the Facebook AI Research Speech team and the creators of Torch and Deep Speech. Flashlight’s ASR application (formerly the wav2letter project) provides training and inference capabilities for end-to-end speech recognition systems. This engine is really performant but you will need to compile all the C++ libraries before using it with Python.
You can find a Google Colab tutorial here that allows you to use Flashlight ASR with Python.
Kaldi
Kaldi is an open source toolkit allowing you to use a speech-to-text engine. Kaldi is written mainly in C/C++, but the toolkit is wrapped with Bash and Python scripts. PyKaldi is the Python scripting layer for the Kaldi speech recognition toolkit. It provides easy-to-use, low-overhead, first-class Python wrappers for the C++ code in Kaldi libraries. See how to use it here.
Cloud Speech-to-Text engines:
There are many cloud speech-to-text engines on the market and you will have issues choosing the right one. Here are the best providers of the market:
- Assembly AI
- Rev AI
- Speechmatics
- Deepgram
- Voci
- Google Cloud Speech-to-Text
- Amazon Transcribe
- Microsoft Azure Speech-to-Text
All those speech-to-text providers can provide you good performance for your project. Depending on the language (and accent), the quality, the length, the size of your audios, the best engine can vary between all these providers. The only way to know which provider to choose is to compare the performance with your own data (audios).
Eden AI Speech-to-text API:
This is where Eden AI enters in your process. Eden AI Speech-to-text API allows you to use engines from all these providers with a unique API, a unique token and a simple Python documentation.
By using Eden AI, you will be able to compare all the providers with your data, change the provider whenever you want and call multiple providers at the same time. You will pay the same price per request as if you had subscribed directly to the providers APIs and you will not lose latency performance.
Here is how to use speech-to-text engines in Python with Eden AI SDK:

If you want to call another provider, you just need to change the value of the parameter “providers”. You can see all providers available in Eden AI documentation. Of course, you can call multiple providers in the same request in order to compare or combine them.
Moreover, Eden AI allows you to use asynchronous speech-to-text for providers that offer this functionality. It avoids you from waiting for the result of the request.
Conclusion
As you could see in this article, there are many options to use speech-to-text with Python. For developers who do not have data science skills or who want to quickly and simply use speech-to-text engines, there are many open source and cloud engines available. Each option presents pros and cons, you know have the clues to choose the best option for you.
If you choose a cloud speech-to-text engine, you will need some help to find the best one according to your data. Moreover, speech-to-text providers often update and train their models. It means that you may have to change your provider’s choice in the future to keep having the best performance for your project. With Eden AI, all this work is simplified and you can set up a speech-to-text engine in Python in less than 5 minutes, and switch to the best provider at any moment.
You can create your Eden AI account here and get your API token to start implementing a speech-to-text engine in Python!





{kind=link}