














The pipeline for an NLP project (or any ML project, for that matter) consists of several steps, including data processing, model training, and deployment. Another step that should be involved between model training and deployment is model evaluation. Only after evaluating a newly trained model should we consider the next steps, which could involve registering and/or deploying the model, or, if the model performance is poor, retraining it with different/more data:
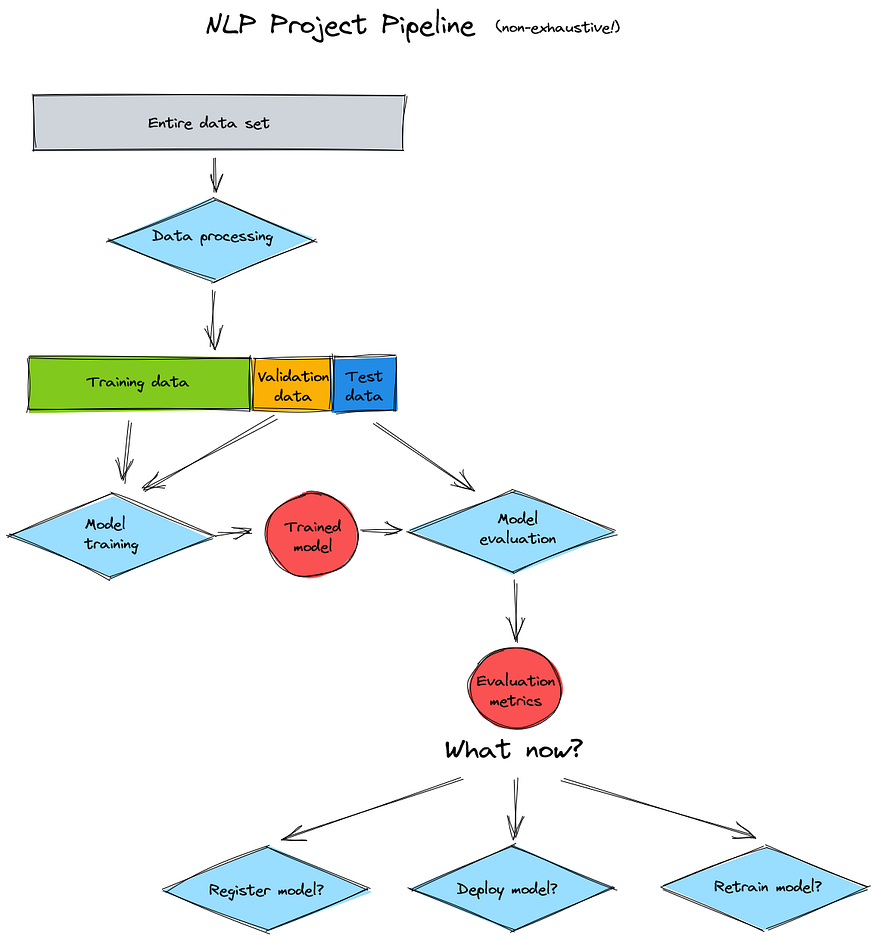
NLP Project Pipeline (image by author)
Amazon SageMaker has recently introduced Hugging Face Processing jobs which are specifically designed and optimized for Hugging Face’s Transformer models. Processing jobs can be used for a variety of tasks: Data pre- or post-processing, feature engineering, data validation, and model evaluation.
In this blog post, we will dive deeper into the last task on that list — model evaluation. We will learn about the challenges of model evaluation and how we can leverage SageMaker Processing jobs to overcome these challenges.
Why is this important?
NLP model evaluation can be resource-intensive, especially when it comes to Transformer models that benefit greatly from GPU acceleration. As a result, the evaluation can take hours if we were to run it on a machine without GPU, especially if the test dataset is large. In fact, we will see exactly how long model evaluation on my laptop (without GPU) takes. In contrast, we will then see that we can speed up this process up to 267(!) times by using SageMaker’s Hugging Face Processing jobs.
Not only do these Processing jobs allow for a faster model evaluation by using on-demand compute resources, but the tight integration within the SageMaker ecosystem also allows for this step to be seamlessly integrated into an end-to-end NLP pipeline.
Prerequisites
The Github repo for this tutorial can be found here. It contains a notebook to interact with the SageMaker Processing job as well as two evaluation scripts — one for evaluating a model on a local machine (e.g. personal laptop) and one for the SageMaker Processing job.
We also need a trained Transformer model and a corresponding test dataset. Ideally, you would use your own model and test data for this, but in case you don’t have those readily available, you can find a model and test data in the Github repo as well.
(The model in the repo is a binary classification model based on DistilBERT that has been fine-tuned to detect positive and negative sentiment in movie reviews. The dataset is in the format of HuggingFace’s Datasets.)
How to evaluate a Transformer model using the Trainer API
Hugging Face’s Trainer API is usually used for training the models, but it also makes it very easy and straightforward to just evaluate an already trained model. We only need to call the Trainer API with the model we want to evaluate, specify the test data, and a definition of the metrics we want to compute to evaluate the model:
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(labels, preds, average="binary")
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1, "precision": precision, "recall": recall}
model = AutoModelForSequenceClassification.from_pretrained('model')
test_dataset = load_from_disk('test_data')
trainer = Trainer(
model=model,
compute_metrics=compute_metrics,
)
eval_result = trainer.evaluate(eval_dataset=test_dataset)
print(eval_result)Evaluating the model locally
By using the script evaluate-local-hf.py from the Github repo we can now evaluate the model wherever we want. In fact, I ran the script on my laptop (which doesn’t have a GPU) to see how long it takes. BUT: The test data consists of ~15K records, which is actually not all that much in today’s day and age where the number of records in an NLP project can easily go up to the millions. However, it is still enough to keep my laptop busy for hours. So instead of using the whole test dataset, I trimmed it down to just 100 records:
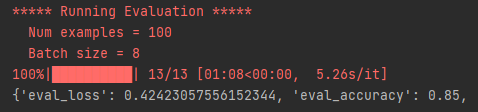
Turns out that processing 100 records take around 68 seconds to run, ~5.3 seconds per batch of 8 records (or 0.66s per record). Extrapolating this to the entire dataset of 15K records means that the model evaluation would have taken ~3h on my laptop.
Sagemaker Processing jobs for Hugging Face
SageMaker Processing allows us to provision a GPU machine on demand, and only for the time needed to evaluate the model. To do so, we use a slightly modified evaluation script that can interact with the Processing job. And this time we will run the evaluation on the entire test dataset, i.e. ~15K records.
To set up the model evaluation we use the SageMaker Python SDK to set up the Processing job:
from sagemaker.huggingface.processing import HuggingFaceProcessor
hf_processor = HuggingFaceProcessor(
role=role,
instance_type="ml.p3.2xlarge",
transformers_version='4.6',
pytorch_version='1.7',
instance_count=1,
)We also need to tell the processor where to find the model and the test data:
from sagemaker.processing import ProcessingInput, ProcessingOutput
model_data = <S3 URI for model file>
test_data = <S3 URI for test data>
inputs = [ProcessingInput(source=model_data, destination="/opt/ml/processing/model"),
ProcessingInput(source=test_data, destination="/opt/ml/processing/test")]
outputs = [ProcessingOutput(output_name="evaluation", source="/opt/ml/processing/evaluation")]And then we can kick off the model evaluation:
hf_processor.run(
code="scripts/evaluate.py",
inputs=inputs,
outputs=outputs,
)Once the run is complete, we can find the evaluation results in a JSON file on the specified output folder in S3 (in our case the file will be called evaluation.json):

Evaluation results on S3 (image by author)
Opening this file provides us with the evaluation metrics that we specified in our compute_metrics() method along with some other metrics from the Processing job:
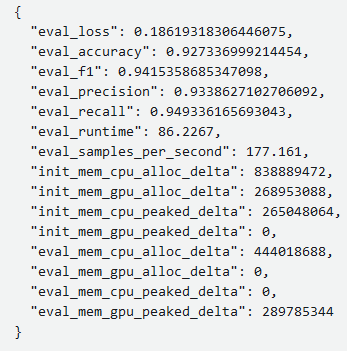
Evaluation metrics (image by author)
In fact, the evaluation results tell us that the Processing job managed to run 177 samples per second. If you recall, my laptop managed to run 0.66 samples per second, which means the processing job ran around 267 times faster than on my laptop! We can see also confirm this by looking at the logs of the Processing jobs:

Runtime on SageMaker (image by author)
As we can see, it took the Processing job only 85 seconds to evaluate the model on a dataset with ~15K records.
Conclusion
In this blog post, we learned how to evaluate an NLP model based on Hugging Face’s Transformer models using Amazon SageMaker Processing jobs. We saw that using GPU compute infrastructure on demand is straightforward on SageMaker and that it speeds up the model evaluation significantly.





{kind=link}