














Introduction
The past year has seen a massive increase in the scope of data related roles. Most aspiring data professionals tend to put a lot of focus on model building, and there is less emphasis placed on other elements of the data science lifecycle.
Due to this, many data scientists are unable to work in an environment outside of a Jupyter Notebook.
They are unable to get their models into the hands of an end-user, and rely on external teams to do this from them. In smaller companies that don’t have a data pipeline in place, these models never see the light of day. They don’t generate any business value, since the company neglected to hire individuals with the required skillset to deploy and monitor models.
In this article, you will learn to export your models and use them outside a Jupyter Notebook environment. You will build a simple web application that is able to feed user input into a machine learning model, and display an output prediction to the user.
By the end of this tutorial, you will learn to do the following:
- Build and tune a machine learning model to solve a classification problem.
- Serialize and save ML models.
- Load these models into different environments, allowing you to work beyond the confines of a Jupyter Notebook.
- Build web applications using Streamlit from a machine learning model.
The web app will take in a user’s demographic and health indicators as input, and generate a prediction as to whether they’d develop heart disease in the next ten years:

Step 1: Background
The Framingham Heart Study is a long-term cardiovascular study of residents of Framingham, Massachusetts. A series of clinical trials were conducted on a group of patients, and risk factors such as BMI, their blood pressure, and cholesterol levels were recorded.
These patients reported to a testing center every few years to provide updated health information.
In this tutorial, we will use a dataset from the Framingham Heart Study to predict whether patients in the study will develop heart disease in ten years. It can be obtained upon request from the BioLincc website, and consists of risk factors of approximately 3600 patients.
Step 2: Pre-requisites
You need to have a Python IDE installed on your device. If you generally work within a Jupyter Notebook, make sure to install another IDE or text-editor. We will be creating a web application using Streamlit, which cannot be run using a notebook.
I suggest writing out your code to build and save the model in Jupyter (Step 3 & Step 4). Then, switch to a different IDE to load your model and run the application (Step 5).
If you don’t already have one installed, here are some options you can choose from: Visual Studio Code, Pycharm, Atom, Eclipse.
Step 3: Model Building
Make sure to download this dataset. Then, import the Pandas library and load the dataframe.
import pandas as pd
framingham = pd.read_csv('framingham.csv')# Dropping null values
framingham = framingham.dropna()
framingham.head()

Taking a look at the head of the dataframe, notice that there are 15 risk factors. These are our independent variables, and we will be using them to predict the onset of heart disease in ten years (TenYearCHD).
Now, let’s take a look at our target variable:
framingham['TenYearCHD'].value_counts()
Notice that there are only two values in this column — 0 and 1. A value of 0 indicates that the patient did not develop CHD in ten years, and a value of 1 indicates that they did.
The dataset is also fairly imbalanced. There are 3101 patients with the outcome of 0 and only 557 patients with an outcome of 1.
To ensure that our model isn’t trained on an imbalanced dataset and predicting the majority class 100% of the time, we will perform random oversampling on the training data. Then, we will fit a random forest classifier onto all the variables in the dataframe.
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import RandomOverSampler
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_scoreX = framingham.drop('TenYearCHD',axis=1)
y = framingham['TenYearCHD']
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.20)oversample = RandomOverSampler(sampling_strategy='minority')
X_over, y_over = oversample.fit_resample(X_train,y_train)rf = RandomForestClassifier()
rf.fit(X_over,y_over)
Now, let’s evaluate model performance on the test set:
preds = rf.predict(X_test)
print(accuracy_score(y_test,preds))
Our model’s final accuracy is approximately 0.85.
Step 4: Saving the Model
Let’s save the random forest classifier we just built. We will use the Joblib library to do this, so make sure you have it installed.
import joblib
joblib.dump(rf, 'fhs_rf_model.pkl')
This model can easily be accessed in different environments, and can be used to make predictions on external data.
Step 5: Building the web app
a) Creating the user interface
Finally, we can start building a web application using the model created above. Make sure to have the Streamlit library installed before we get started.
If you were using a Jupyter Notebook to build the classifier, you now need to move to a different Python IDE. Create a file named streamlit_fhs.py.
Your directory should contain the following files:
Then, import the following libraries in your .py file:
import streamlit as st
import joblib
import pandas as pd
Let’s create a header for our web application and run it to check if everything is working fine:
st.write("# 10 Year Heart Disease Prediction")
To run the Streamlit app, type the following command into the terminal:
streamlit run streamlit_fhs.py
Now, navigate to http://localhost:8501 where your app resides. You should see a page that looks like this:

Great! This means everything’s working.
Now, let’s create input boxes for users to enter their data (their age, gender, BP, etc).
Here’s how to create a multiple choice drop-down in Streamlit for users to select their gender (This is sample code. Delete this line once you run it, the complete example can be found below):
gender = st.selectbox("Enter your gender",["Male", "Female"])
Navigate to your Streamlit app again and refresh the page. You will see this drop-down box appear on your screen:
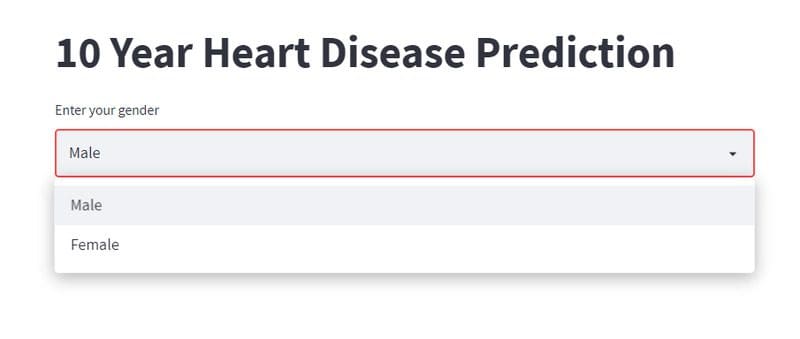
Remember, we have 15 independent variables we need to collect from the user.
Run the following lines of code to create input boxes for users to enter data into. We will divide the page into three columns to make the app more visually appealing.
col1, col2, col3 = st.columns(3)
# getting user inputgender = col1.selectbox("Enter your gender",["Male", "Female"])
age = col2.number_input("Enter your age")
education = col3.selectbox("Highest academic qualification",["High school diploma", "Undergraduate degree", "Postgraduate degree", "PhD"])
isSmoker = col1.selectbox("Are you currently a smoker?",["Yes","No"])
yearsSmoking = col2.number_input("Number of daily cigarettes")
BPMeds = col3.selectbox("Are you currently on BP medication?",["Yes","No"])
stroke = col1.selectbox("Have you ever experienced a stroke?",["Yes","No"])
hyp = col2.selectbox("Do you have hypertension?",["Yes","No"])
diabetes = col3.selectbox("Do you have diabetes?",["Yes","No"])
chol = col1.number_input("Enter your cholesterol level")
sys_bp = col2.number_input("Enter your systolic blood pressure")
dia_bp = col3.number_input("Enter your diastolic blood pressure")
bmi = col1.number_input("Enter your BMI")
heart_rate = col2.number_input("Enter your resting heart rate")
glucose = col3.number_input("Enter your glucose level")
Refresh the app again to view changes:

Finally, we need to add a ‘Predict’ button to the bottom of the page. Once users click on this button, the output will be displayed.
st.button('Predict')
Great! You will see this button after refreshing the page again.
b) Making predictions
The app interface is ready. Now, all we need to do is collect user input every time it enters the system. We need to pass this data to our classifier in order to come up with an output prediction.
User input is now stored in the variables we created above — age, gender, education, etc.
However, this input isn’t in a format that can be easily ingested by the classifier. We are collecting strings in the form of Yes/No questions, and this needs to be encoded in the same way that the training data was.
Run the following lines of code to transform the user-input data:
df_pred = pd.DataFrame([[gender,age,education,isSmoker,yearsSmoking,BPMeds,stroke,hyp,diabetes,chol,sys_bp,dia_bp,bmi,heart_rate,glucose]],
columns= ['gender','age','education','currentSmoker','cigsPerDay','BPMeds','prevalentStroke','prevalentHyp','diabetes','totChol','sysBP','diaBP','BMI','heartRate','glucose'])
df_pred['gender'] = df_pred['gender'].apply(lambda x: 1 if x == 'Male' else 0)
df_pred['prevalentHyp'] = df_pred['prevalentHyp'].apply(lambda x: 1 if x == 'Yes' else 0)
df_pred['prevalentStroke'] = df_pred['prevalentStroke'].apply(lambda x: 1 if x == 'Yes' else 0)
df_pred['diabetes'] = df_pred['diabetes'].apply(lambda x: 1 if x == 'Yes' else 0)
df_pred['BPMeds'] = df_pred['BPMeds'].apply(lambda x: 1 if x == 'Yes' else 0)
df_pred['currentSmoker'] = df_pred['currentSmoker'].apply(lambda x: 1 if x == 'Yes' else 0)def transform(data):
result = 3
if(data=='High school diploma'):
result = 0
elif(data=='Undergraduate degree'):
result = 1
elif(data=='Postgraduate degree'):
result = 2
return(result)df_pred['education'] = df_pred['education'].apply(transform)
We can just load the model we saved earlier and use it to make predictions on values entered by the user:
model = joblib.load('fhs_rf_model.pkl')
prediction = model.predict(df_pred)
Finally, we need to display these predictions on the screen.
Navigate to the line of code where you created your predict button earlier, and modify it as shown below:
if st.button('Predict'):
if(prediction[0]==0):
st.write('<p class="big-font">You likely will not develop heart disease in 10 years.</p>',unsafe_allow_html=True)
else:
st.write('<p class="big-font">You are likely to develop heart disease in 10 years.</p>',unsafe_allow_html=True)
These changes have been added so that the output is only displayed once the user clicks on the Predict button. Also, we want text to be displayed to the user instead of just showing them the prediction values (0 and 1).
Save all your code and refresh your page again, and you will see the completed application on your screen. Add in random input numbers and click on the Predict button to make sure everything works:

If you followed along to the entire tutorial, congratulations! You have successfully built a ML web application with Streamlit that is able to interact with end-users.





{kind=link}